
対応のあるt検定の適用の条件
対応のあるt検定を適用するためにはいくつかの条件を満たす必要があります.
ここではまず対応のあるt検定を適用するための4つの条件をお示しいたします.
・正規分布に従うデータ(正規性の判断についてはコチラを参照してください)
・データが比率尺度データまたは間隔尺度データ
(例外として多段階の順序度データでも使用することあります)
・平均を比較することが意味を持つデータ
・1つの標本に対して条件を変えて得た2つのデータ
(3つ以上になると異なる検定を使用する必要があります)
対応があるって何?
対応があるというのは比べるデータが同一対象者のデータであることを意味します
ここで重要なのは対応のあるt検定というのは1つの標本に対して用いられる検定であるといった点です.
例えばダイエット前後で体重を比較するとか,塾に通う前後で成績を比較するといったような場合には,同一対象のデータを前後で比較することとなります.
このように同一対象の2つのデータを比較する場合には対応のある検定を用いることとなります.
SPSSを使用した対応のあるt検定-データの並べ方に注意-
SPSSでt検定を行う場合にはデータの並べ方にも注意が必要です.
実は対応のある検定と対応の無い検定ではデータの並べ方も異なるものとなります.
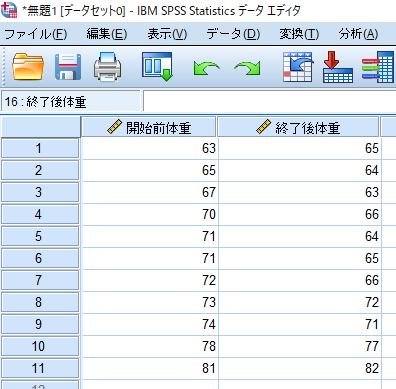
対応のある検定の場合には,このように横列に同一対象者のデータ(ダイエット前後での体重)を並べます.
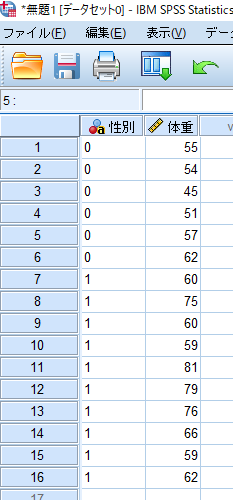
対応の無い検定の場合には,測定データ(体重)を縦列に並べ,その横にグループを表すデータ(性別等:男性=0,女性=1)を入力します.
SPSSを使用した対応のあるt検定の方法
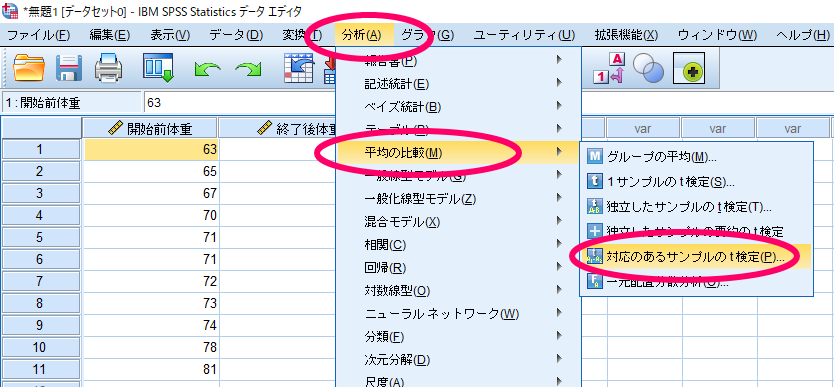
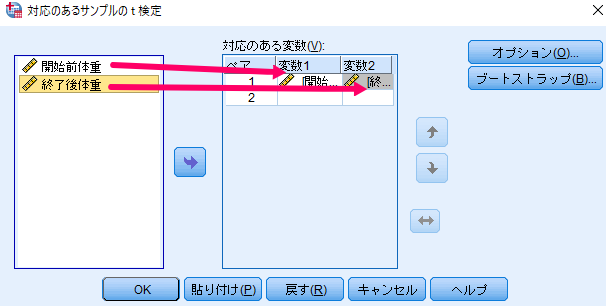
比較したい組み合わせが複数存在する場合には,ペア2,ペア3を使用すれば,様々な組み合わせで比較を行うことができます.
ここではダイエット開始前・終了後の2群の比較ですのでペア1のみの比較となります.
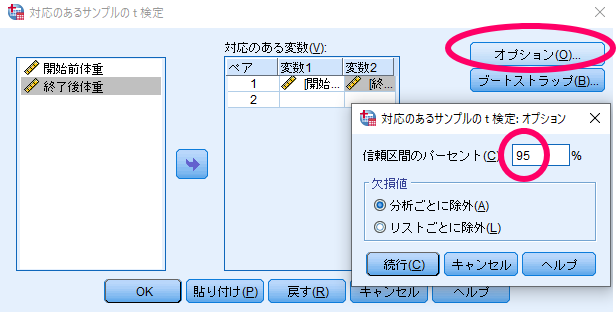
信頼区間は95%に設定することが多いが,場合によっては99%が用いられることもあります.
SPSSを使用した対応のあるt検定の結果の見方・確認方法

これが対応のあるt検定の結果です.
対応のあるt検定を結果を確認する際には見るポイントが5つあります.
①平均値
ダイエット開始前の体重とダイエット終了後の体重の平均値がそれぞれ出力されておりますので,まずは平均値を確認しましょう.
平均値と合わせて算出されている標準偏差も確認しましょう.
平均値と標準偏差を見れば,集団のデータがどの範囲にあるのかがおおよそ把握できます.
この有意確率を見れば,最終的にダイエット前後での体重に変化があったのかどうかがわかります.
有意確率(p)<0.05:差がある
有意確率(p)≧0.05:差がない(厳密にいえばあるともないとも言えない)
この場合には,有意確率が0.012で5%未満ですので,前後で有意な差があるといった解釈ができます.
差の95%信頼区間を確認すると,下限が0.732,上限が4.722と出力されているのがわかります.
95%信頼区間って何?
簡単に言うとダイエット前後での差が95%の確率でどの範囲にあるかを表すものです
この場合で言うとダイエット前後での体重の変化は,95%の確率で0.732~4.722の間にあるという解釈になります.
つまりダイエット前後での体重の変化は1kgにも満たない場合もあるし,ダイエット前後での体重の変化が5.0kg近いこともあるといったわけです.
ここで重要なのは今回は差の95%信頼区間が0をまたいでいない(下限値が負の値になっていない)という点です.
有意確率が5%以上となっている場合には,95%信頼区間が0をまたぐ(下限値が負の値になる)ようになります.
さらにこの95%信頼区間の大きさを確認することで,差がどのくらい意味のあるものかを判断することができます.
例えば有意確率が5%未満であっても,差の95%信頼区間が0.1~0.2であったのであれば,そんな差はあまり意味のない差としてとらえることができるでしょう.
逆に有意確率が5%未満で,かつ差の95%信頼区間が5.0~7.0といったデータであればダイエットによる変化が非常に大きいと判断できるでしょう.
この自由度やt値というのはいわゆる統計量と呼ばれるものです.
素人が理解しておく必要はあまりないものですが,効果量を算出する上ではこの自由度とt値が必要となります.
効果量についてはまた後でご紹介させていただきますので,ここでは効果量を算出するために必要な数値であるくらいの認識で良いと思います.
SPSSを用いて対応のあるt検定を行った際のグラフ作成
対応のあるt検定を用いる場合にはデータに正規性が確認できることが前提となりますので,対応のあるt検定を用いた場合に使用すべきグラフは平均値と95%信頼区間を用いたエラーバーグラフです.
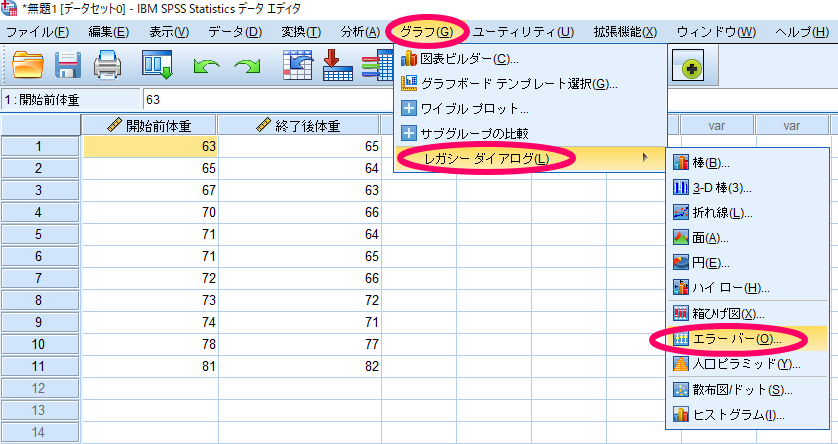
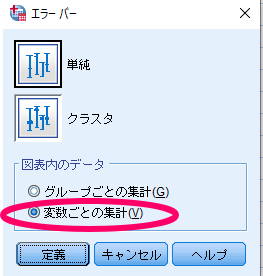
ここで重要なのは対応のあるデータの場合には,図表内のデータで「変数ごとの集計」を選択する点です.
ちなみに対応の無いデータを用いてエラーバーグラフを作成する場合には,図表内のデータで「グループごとの集計」を選択する必要があります.
最後に「定義」をクリックします.
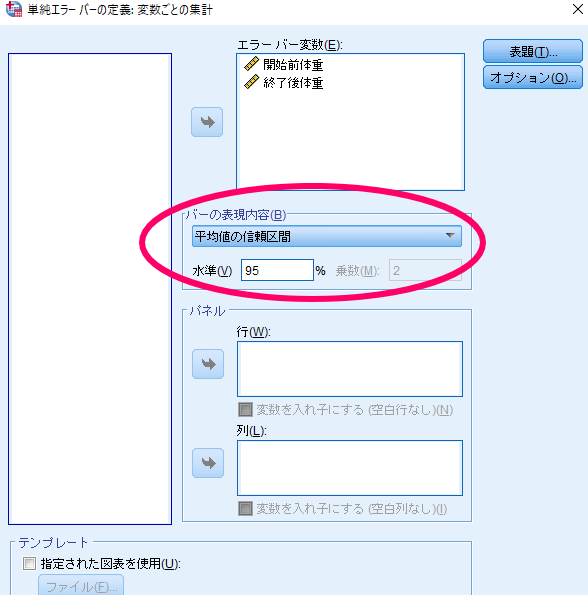
デフォルト設定は平均値の95%信頼区間となっておりますが,標準誤差や標準偏差を用いてグラフを作成することも可能です.
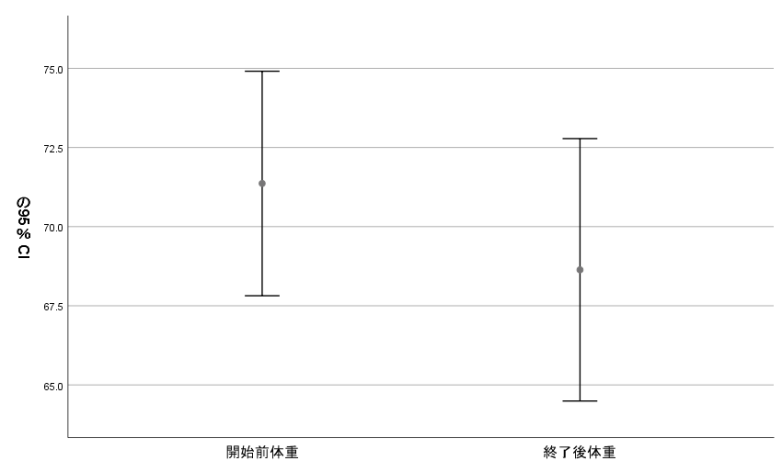
これが完成したエラーバーグラフです.
中央の小さい●印が平均値,上下のバーが95%信頼区間を表しております.
対応のあるt検定における効果量(r・d)の算出
最近は対応のあるt検定を行った場合には,有意確率・95%信頼区間と合わせて効果量(rやd)を算出するのが一般的になってきております.
はじめにSPSSでは効果量を算出することはできませんので,先ほどお示しいたしました自由度やt値といった統計量を使用して効果量を算出することになります.
ところで効果量って何?
効果量というのはデータの単位に依存しない標準化された効果の程度を表す指標です.
先ほどダイエット前後での体重の変化量に関して変化の大きさを95%信頼区間を用いて考察いたしました.
例えばある研究ではダイエット効果をアウトカムを体重(kg)を用いて検討を行っていたのに対して,ある研究ではダイエット効果を,CTによる内臓脂肪量(cm2)をアウトカムとして検討を行っていたとします.
この場合にはアウトカムの単位が異なりますので2つの研究の間でどちらが効果があったのかを単純比較することができません.
このように単位の異なる研究から得られた効果の比較や人数の異なる研究から得られた効果を比較する際に役立つのが効果量という指標です.
特にrという効果量と,dという効果量の2種類が代表的です.
rもdも計算方法が異なるだけで意味は同一なのですが,rは0~1(もしくは0~-1)の範囲をとるので理解しやすく,差の検定ではrが用いられることが多いです.
効果量ってどうやって算出するの?
効果量の算出には以下のエクセルファイルがとても便利です.

ここではこのエクセルファイルを用いて効果量(r)を算出いたしました.

先ほどのSPSSを用いて行った対応のあるt検定の結果で得られたt値=3.046と自由度=10を上記のエクセルファイルに打ち込むと簡単に効果量が算出できます.
この場合には効果量(r)=0.69で効果量大と判定されました.
つまり差の程度が効果量から見ても大きいという解釈ができます.
効果量の大きさってどうやって判断するの?
あくまで目安ですが下の表が非常に参考になります.効果量(r)の場合は,相関係数をイメージすると理解しやすいでしょうね.

http://jspt.japanpt.or.jp/ebpt_glossary/effect-size.htmlより引用
![]()


コメント
[…] SPSSでは効果量を算出することはできませんので,対応のあるt検定や対応のないt検定の記事でもご紹介したような方法で自由度やt値といった統計量を使用して効果量を算出することになります. […]