
反復測定による一元配置分散分析(対応のある3群以上の差の検定)の適用の条件
反復測定による一元配置分散分析(対応のある3群以上の差の検定)を適用するためにはいくつかの条件を満たす必要があります.
ここではまず反復測定による一元配置分散分析(対応のある3群以上の差の検定)を適用するための4つの条件をお示しいたします.
・正規分布に従うデータ(正規性の判断についてはコチラを参照してください)
・データが比率尺度データまたは間隔尺度データ
(例外として多段階の順序度データでも使用することあります)
・平均を比較することが意味を持つデータ
・1つの標本に対して3つ以上の条件を変えて,反復測定したデータ
(1つの標本に対して2つの条件を変えて反復測定したデータの場合には対応のあるt検定を使用します)
対応があるって何?
対応があるというのは比べるデータが同一対象例のデータであることを意味します
ここで重要なのは反復測定による一元配置分散分析というのは1つの標本に対して3つ以上の条件を変えて反復測定したデータに用いられる検定であるといった点です.
例えばダイエットを行った場合に,ダイエット開始前・ダイエット開始1か月後・ダイエット開始3か月後で体重を比較するとか,体組成率の日差変動をみるために朝・昼・夜に体組成率を測定して比較するいったような場合には,同一対象例の3条件のデータを比較することとなります.
このように同一対象例を対象として3条件以上のデータを比較する場合には反復測定による一元配置分散分析を用いることとなります.
ちなみに対応のない3条件以上の比較にはデータに正規性が確認できれば,一元配置分散分析を用いることとなります.
SPSSを使用した反復測定による一元配置分散分析-データの並べ方に注意-
SPSSで反復測定による一元配置分散分析を行う場合にはデータの並べ方にも注意が必要です.
実は対応のある検定と対応の無い検定ではデータの並べ方も異なります.
3群以上の差の検定で用いられるパラメトリック検定には,一元配置分散分析(対応のない検定)と反復測定による一元配置分散分析(対応のある検定)といった手法がありますが,一元配置分散分析と反復測定による一元配置分散分析ではデータの並べ方も異なるものとなりますので,注意が必要です.
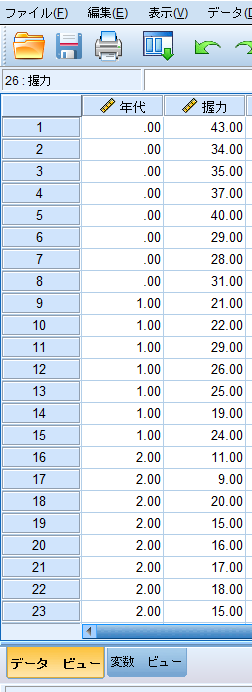
一元配置分散分析の場合には,測定データ(体重)を縦列に並べ,その横にグループを表すデータ(年代:若年者=0,前期高齢者=1,後期高齢者=2)を入力します.
SPSSにデータを移行する前にエクセルでデータベースを作成することが多いと思いますが,エクセルでデータ整理をする段階でこのようなデータのまとめ方をしておくと,エクセルからSPSSへのデータ移行が容易となります.
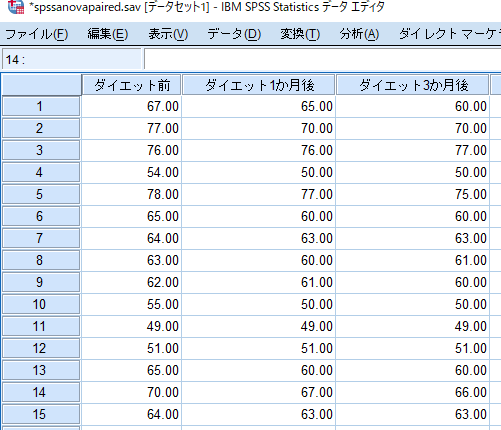
ちなみに反復測定による一元配置分散分析の場合にはこんな感じです.
対応のある検定の場合には,このように横列に同一対象者のデータを並べます.
SPSSにデータを移行する前にエクセルでデータベースを作成することが多いと思いますが,エクセルでデータ整理をする段階でこのようなデータのまとめ方をしておくと,エクセルからSPSSへのデータ移行が容易となります.
SPSSを使用した反復測定による一元配置分散分析の方法
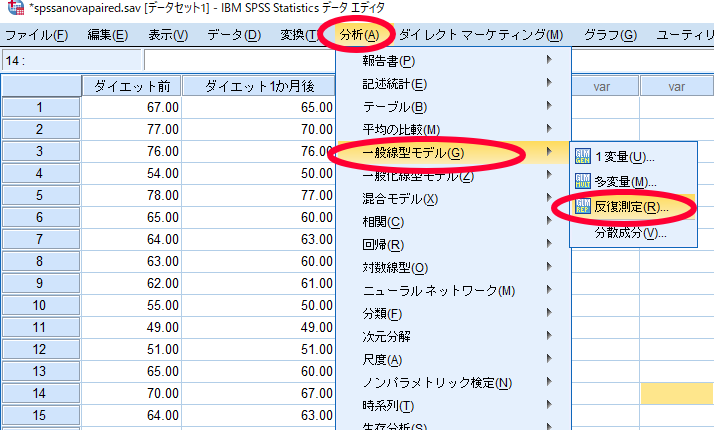
ここではダイエット前・ダイエット1か月後・ダイエット3か月後に体重のデータを比較する例をお示ししながら話を進めていきます.
反復測定による一元配置分散分析は正規分布のデータに用いられる統計手法ですので,事前にShapiro-wilk検定を用いて正規性の検定を行っておく必要があります.

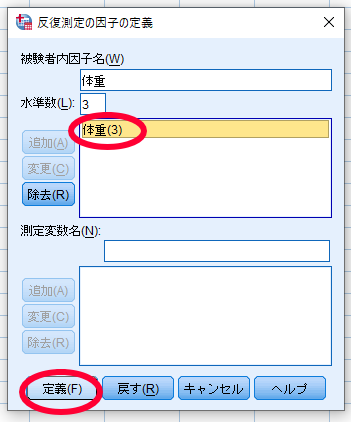
水準数の下の空欄に被検者内因子名(水準数)(ここでは体重(3))が表記されていることを確認して,定義をクリック
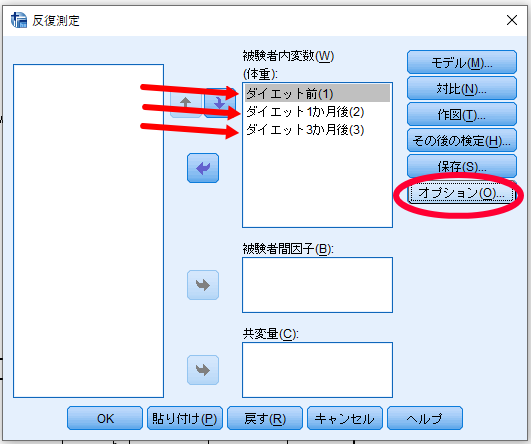
検者内変数へダイエット前・ダイエット1か月後・ダイエット3か月後を移動します.
移動が終わったらオプションをクリックします.
反復測定による一元配置分散分析では事後検定(多重比較法)を選択する必要がありますので,その後の検定の設定を行います.
多重比較法と呼ばれる検定手法は分散分析による結果が有意であった場合に,1つ1つの水準(ここではダイエット前・ダイエット1か月後・ダイエット3か月後)の間のどこに有意な差があるのかを明らかにするために行います.
分散分析が有意であった場合には,水準(ここではダイエット前・ダイエット1か月後・ダイエット3か月後)間のどこかに差があることはわかりますが,どこに差があるかまではわかりませんので,どことどこに差があるかを多重比較法を用いて明らかにするわけです.
反復測定による一元配置分散分析ではBonferroni法を選択することとなります.

因子と交互作用の欄から「体重」を平均値の表示の欄へ移動させます.
主効果の比較にチェックを入れて,Bonferroni法を選択します.
ちなみにBonferroni法の欠点として差が出にくいといった特徴が挙げられます.
SPSSではBonferroni法以外に反復測定による一元配置分散分析後の多重比較法がありませんので,Bonferroni法を実施するしかありませんが,手計算でHolm法を行う等の方法もあります.
最後に続行をクリックして,OKをクリックすれば検定が完了します.
SPSSを使用した反復測定による一元配置分散分析の結果の見方・確認方法
反復測定による一元配置分散分析の結果を確認する際には見るポイントがいくつかあります.
①Mauchlyの球面性検定の結果
まずはMauchlyの球面性の検定の結果を確認します.
分散分析を行うためには,各水準間の「差」の分散が等しいことが条件となります.
これを球面性の仮定とよびます.
この仮定が満たされない(等分散でない)場合には,自由度を調整して有意性の検定を行う必要があります.
SPSSではMauchlyの球面性の検定が自動的に行われますので,球面性の検定の結果を参照した上で球面性が仮定できない場合にはGreenhouse-Geisserのε補正を行った有意確率を参照することとなります.
球面性の検定ってどうやるの?
実はSPSSでは自動的に球面性の検定を行ってくれます.Mauchlyの球面性検定と呼ばれる検定を自動で行ってくれるわけです.
基本的にはMauchlyの球面性検定における有意確率に応じて出力の参照する部分が異なります
有意確率(p)<0.05:球面性が仮定できる(不等分散)⇒平均値同等性の耐久検定を参照
有意確率(p)≧0.05:球面性が仮定できる(等分散)⇒分散分析の結果を参照
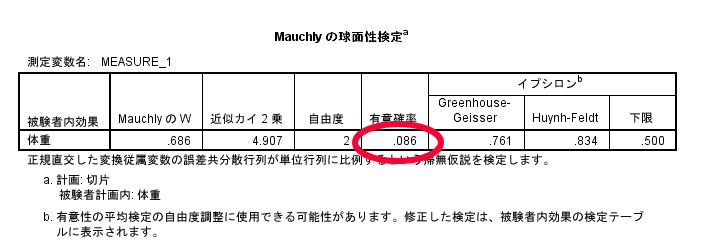
今回のデータでは,Mauchlyの球面性検定の結果,有意確率が0.86と出力されております.
今回のデータでは,Mauchlyの球面性検定の結果,有意確率が0.86と出力されておりますので,等分散と判断できますので,分散分析の結果(被検者内効果の検定)の中の球面性の検定(①にあたる部分)を参照することとなります.
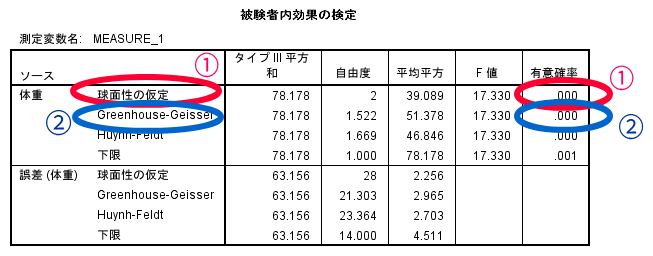
仮にMauchlyの球面性検定の結果がp<0.05となった場合には,②のGreenhouse-Geisserの有意確率を参照することとなります.
被検者内効果の検定の結果,有意確率が0.00<0.05となっておりますので,この結果からダイエット前・ダイエット1か月後・ダイエット3か月後の3群の中でどこかに差があるといった判断ができます.
ちなみに反復測定による一元配置分散分析における有意確率は以下のように解釈します.
有意確率(p)<0.05:3群のどこかに差がある
有意確率(p)≧0.05:3群のどこにも差がない(厳密にいえばあるともないとも言えない)
ただここまでの結果からは具体的にどことどこに差があるのかはわかりません.
この分散分析の結果には自由度やF値も算出されている点にも注目です.
自由度やF値は論文でも統計量として公表が求められることが多いです.
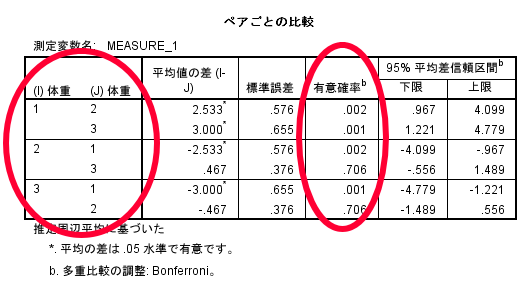
これがBonferroni法による多重比較の結果です.
反復測定による一元配置分散分析ではダイエット前・ダイエット1か月後・ダイエット3か月後の体重のデータのどこかに差があることと判断できるわけですが,具体的にどことどこに差があるかをみる場合にはこのBonferroni法の結果を参照する必要があります
この表の見方は以下の通りです.
1列目:ダイエット開始前とダイエット開始1か月後の差
2列目:ダイエット開始前とダイエット開始3か月後の差
3列目:ダイエット開始1か月後とダイエット開始前の差
4列目:ダイエット開始1か月後とダイエット開始3か月後の差
5列目:ダイエット開始3か月後とダイエット開始前の差
6列目:ダイエット開始3か月後とダイエット開始1か月後の差
よく見てみると前後が反対になっているだけで赤色の部分だけを見れば,ダイエット開始前とダイエット開始1か月後,ダイエット開始前とダイエット開始3か月後,ダイエット開始1か月後とダイエット開始3か月後といった3群間の差が明らかとなります.
ここでも以下のように判断します.
有意確率(p)<0.05:2群に差がある
有意確率(p)≧0.05:2群に差がない(厳密にいえばあるともないとも言えない)
1列目:ダイエット開始前とダイエット開始1か月後の差⇒p=0.002
2列目:ダイエット開始前とダイエット開始3か月後の差⇒p=0.001
4列目:ダイエット開始1か月後とダイエット開始3か月後の差⇒p=0.706
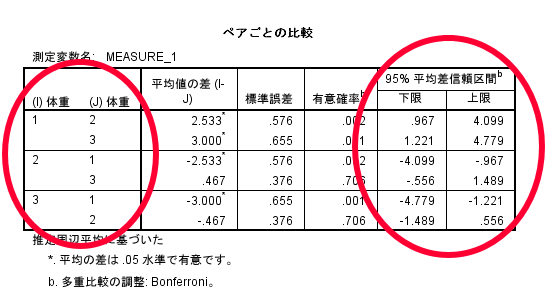
1列目のダイエット開始前とダイエット開始1か月後の体重差の95%信頼区間は,0.967~4.099であることがわかります.
95%信頼区間って何?
簡単に言うとダイエット開始前とダイエット開始1か月後の体重差が95%の確率でどの範囲にあるかを表すものです
この場合で言うと若年者と前期高齢者の間の握力差は,95%の確率で0.967~4.099kgの間にあるという解釈になります.
つまり男女間の体重の差は1kg程度の場合もあるし,4kgを超える場合もあると解釈できます.
ここで重要なのは今回は差の95%信頼区間が0をまたいでいない(この場合,下限値が負の値になっていない)という点です.
有意確率が5%未満となっている場合には,95%信頼区間が0をまたぎません.
さらにこの95%信頼区間の大きさを確認することで,差がどのくらい意味のあるものかを判断することができます.
例えば有意確率が5%未満であっても,差の95%信頼区間が0.1~0.2であったのであれば,そんな差はあまり意味のない差としてとらえることができるでしょう.
今回のデータでは有意確率が5%未満で,かつ差の95%信頼区間が0.967~4.099kgですからダイエットによる減量は1kg未満の場合もあり,誤差レベルの可能性もあると捉えることもできるでしょう.
SPSSを用いて反復測定による一元配置分散分析を行った際のグラフ作成
反復測定による一元配置分散分析を用いる場合にはデータに正規性が確認できることが前提となりますので,一元配置分散分析を用いた場合に使用すべきグラフは平均値と95%信頼区間を用いたエラーバーグラフです.
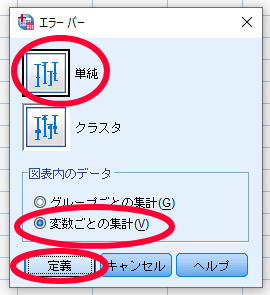
ここで重要なのは対応のあるデータの場合には,図表内のデータで「変数ごとの集計」を選択する点です.
ちなみに対応のないデータを用いてエラーバーグラフを作成する場合には,図表内のデータで「グループごとの集計」を選択する必要があります.
最後に「定義」をクリックします.
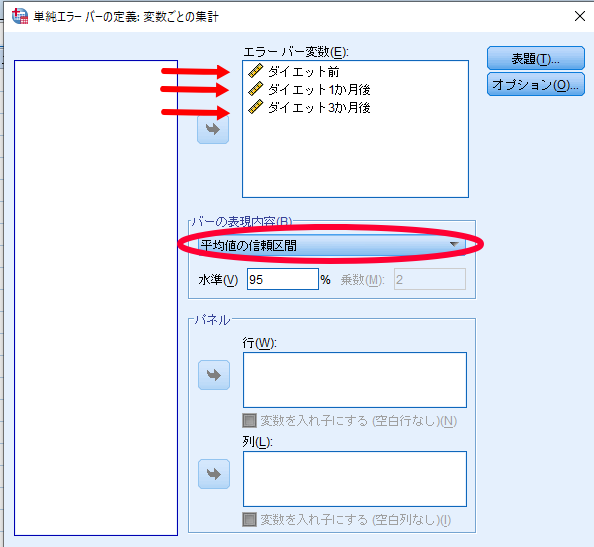
ダイエット前・ダイエット1か月後・ダイエット3か月後をエラーバー変数へ移動させます.
デフォルト設定は平均値の95%信頼区間となっておりますが,標準誤差や標準偏差を用いてグラフを作成することも可能です.

これが完成したエラーバーグラフです.
中央の小さい●印が平均値,上下のバーが95%信頼区間を表しております.
反復測定による一元配置分散分析における効果量(η2)の算出
最近は反復測定による一元配置分散分析を行った場合には,有意確率・95%信頼区間と合わせて効果量(η2)を算出するのが一般的になってきております.
はじめにSPSSでは効果量を算出することはできませんので,平方和といった統計量を使用して効果量を算出することになります.
ところで効果量って何?
効果量というのはデータの単位に依存しない標準化された効果の程度を表す指標です.
単位の異なる研究から得られた効果の比較や人数の異なる研究から得られた効果を比較する際に役立つのが効果量という指標です.
一元配置分散分析ではη2が用いられます.
ちなみにηの読み方ですがエータと読みます.
ηは0~1(もしくは0~-1)の範囲をとるので理解しやすいです.
効果量ってどうやって算出するの?
効果量の算出には以下のエクセルファイルがとても便利です.

ここではこのエクセルファイルを用いて効果量(η2)を算出いたしました.
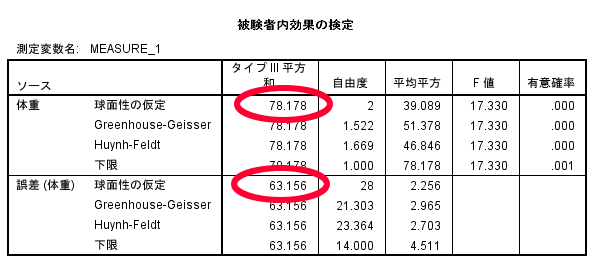
効果量(η2)の算出に当たっては効果の平方和と誤差の平方和を使います.
ここでは効果の平方和=78.178をグループ間の平方和へ入力します.
また効果の平方和=78.178に誤差の平方和=63.156を加算したもの(141.33)をエクセルシートへそのまま打ち込みます.
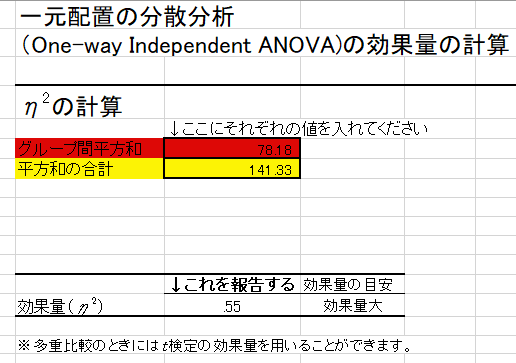
この場合には効果量(η2)=0.55で効果量大と判定されました.
つまり差の程度が効果量から見ても大きいという解釈ができます.
効果量の大きさってどうやって判断するの?
あくまで目安ですが下の表が非常に参考になります.効果量(r)の場合は,相関係数をイメージすると理解しやすいでしょうね.
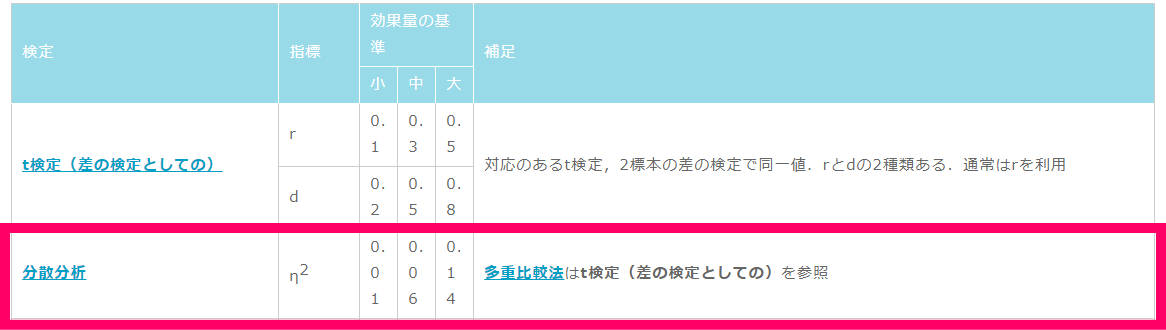
http://jspt.japanpt.or.jp/ebpt_glossary/effect-size.htmlより引用
![]()


コメント