
サンプルサイズの計算がなぜ必要なのか?
なぜかというと統計学的検定というのは,仮に有意確率P値が0.05未満であっても,その結果が偶然ということもあり得るからです
統計学的検定には実はからくりがあって,サンプルサイズ(n数)が大きくなると,必然的にP値は小さくなります.
カイ2乗検定(χ2検定)ではχ2値と呼ばれる統計量を使用して,有意かどうかを判断します.
χ2値は以下の数式で算出されます.

少しややこしい数式ですが重要なのはNが大きくなるとχ2値が大きくなるといった点です.
χ2値が大きくなるとP値が小さくなりますので,χ2値が大きいほどカイ2乗検定(χ2検定)では有意な結果が出やすくなります.
このようにサンプルサイズが大きくなると,有意な結果が出やすくなってしまうわけです.
統計学的には有意な結果があってもnが大きいから差が偶然出るってことがあるの?
その通りです.本当に2群間の割合に差があって有意差が出る場合もあれば,サンプルサイズが大きいために2群間の割合に有意差が出るといった場合もあります.
したがって適切なサンプルサイズで統計学的な検定を行わないと,サンプルサイズが大きかったから有意差が出たということになってしまいます.
そのため通常は,事前にサンプルサイズを決定して必要なサンプルサイズを決定してから,研究を行うことが重要となります.
G*powerを用いて事前にサンプルサイズを決定するためは何が必要か?
サンプルサイズの計算がなぜ必要なのかについてはご理解いただけたかと思います.
サンプルサイズってどうやって決めればよいの?
サンプルサイズを決定するためには,3つの要因を決定する必要があります
- 1.効果量
2.αエラー
3.検出力(βエラー)
ここからはこの3つの要因の決め方についてご説明いたします.
効果量にはいくつかの設定方法があります.
まずサンプルサイズを事前設計する(研究を行う前にサンプルサイズを決める)場合には,①先行研究における効果量を用いる方法,②予備調査における効果量を用いる方法,③中間解析データを用いる方法があります.
自身の研究と類似した研究があれば,類似した研究の効果量を用います.
この場合にはカイ2乗検定(χ2検定)における効果量(w)を算出する必要があります.
カイ2乗検定(χ2検定)における効果量(w)がわからない場合には,クロス集計表の割合がわかればG*powerを用いて効果量(w)を算出することが可能です.
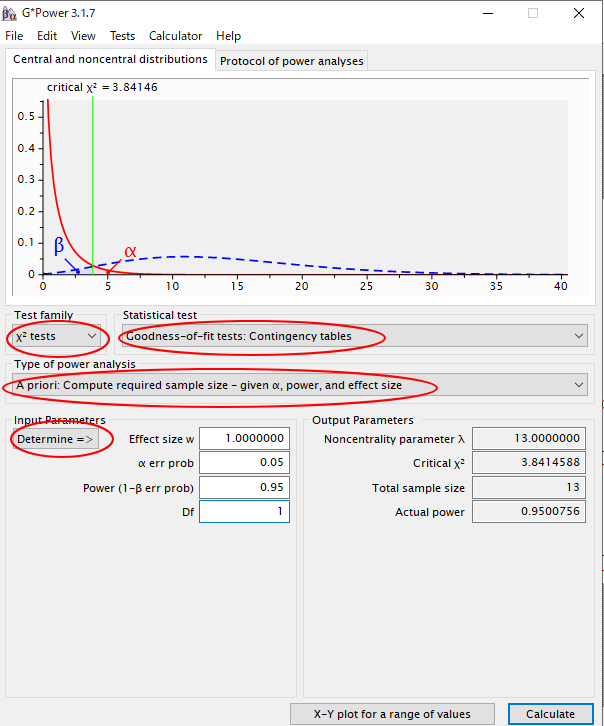
Test family⇒χ2 testを選択
Statistical test⇒Goodness of fit tests: Contingency tablesを選択
Type of power analysis⇒A priori:Compute required sample size
Determineをクリックして効果量(w)を計算
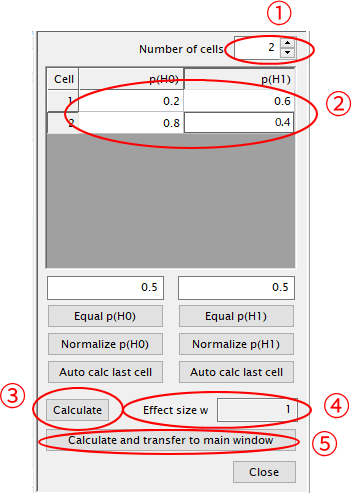
①クロス集計表の縦列・横列に合わせてNumber of cellを調整(ここでは性別×骨粗鬆症の有無の2×2を想定して”2″を選択)
②クロス集計表における割合を入力(男性で骨粗鬆症を有する者:0.2,男性で骨粗鬆症を有しない者:0.8,女性で骨粗鬆症を有する者:0.6,女性で骨粗鬆症を有しない者:0.4といった形式です)
③Calculateをクリック
④効果量(w)=1.000を確認
⑤Calculate and transfer to main windowをクリック
これで効果量(Effect size w)のところに”1.000″と表示されるのが確認できます.
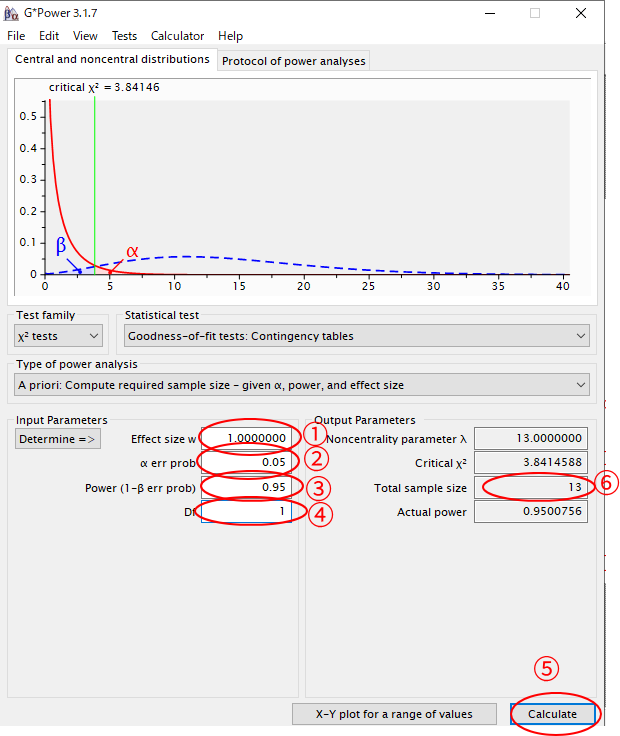
①効果量(Effect size d)のところに”1.000″の表示を確認
②αエラーを設定します.通常は0.05としますが,0.01でもかまいません
③検出力(1-βエラー)を設定します.デフォルト設定では0.95となっておりますが,0.8とされていることも多いです.ここでは0.95としております.通常はβがαの4~5倍になるように設定します.
④Dfは1と入力
⑤Calculateをクリック
⑥最終的に13例のサンプルサイズが妥当だといった結論が得られます.
予備調査における効果量を用いる場合も基本的には先行研究における効果量を用いる方法と同様です.
予備調査におけるクロス集計の割合を用いて効果量を算出した上で,サンプルサイズの設計を行います.
中間解析とはある程度,測定を行った段階で解析を行い,残りどのくらいのサンプルが必要かを検討する方法です.
中間解析における効果量を用いる場合も基本的には先行研究における効果量を用いる方法と同様です.
中間解析におけるクロス集計の割合を用いて効果量を算出した上で,サンプルサイズの設計を行います.
最終的に算出されたサンプルサイズを目標に残りの調査を行うこととなります.
事前にサンプルサイズを設計できなかった場合には事後にG*powerを用いてサンプルサイズが適当だったか検出力を確かめよう
サンプルサイズって事前に決めるんでしょ?事後でも対応できるの?
サンプルサイズは事前に設計することが多いですが,事後にサンプルサイズが妥当であったかを調べる方法もあります.これを事後分析と呼びます
ここでG*powerを用いた事後分析の方法をご紹介いたします.
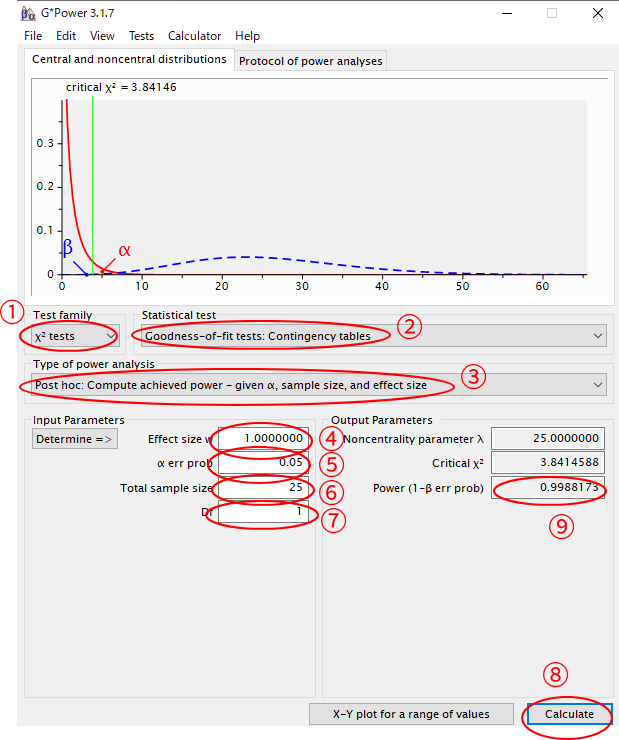
①Test family⇒χ2 testを選択
②Statistical test⇒Goodness of fit tests: Contingency tablesを選択
③Type of power analysis⇒A priori:Compute required sample size
④効果量(w)を入力(効果量(w)を算出していない場合には,Determineをクリックして,クロス集計表の割合から効果量(w)を算出.ここでは仮に”1.0″とします)
⑤αエラーを設定.通常は0.05としますが,0.01でもかまいません検出力(1-βエラー)を設定.
⑥全てのサンプルサイズを入力(ここではn=25とします)
⑦df=1と入力
⑧Calculateをクリック
⑨最終的に検出力が0.998と出力される(検出力が0.80を上回っているので検出力は高いと判断できます).
事後分析の検出力って高ければいいの?
事後分析の検出力が1になっている場合には注意が必要です.検出力が1になっている場合には,サンプルサイズが過大な可能性が考えられます.つまりサンプルサイズが大きいために偶然差が出ている可能性があります.したがって検出力が0.80~1.00の値になることが理想です.

![]()


コメント